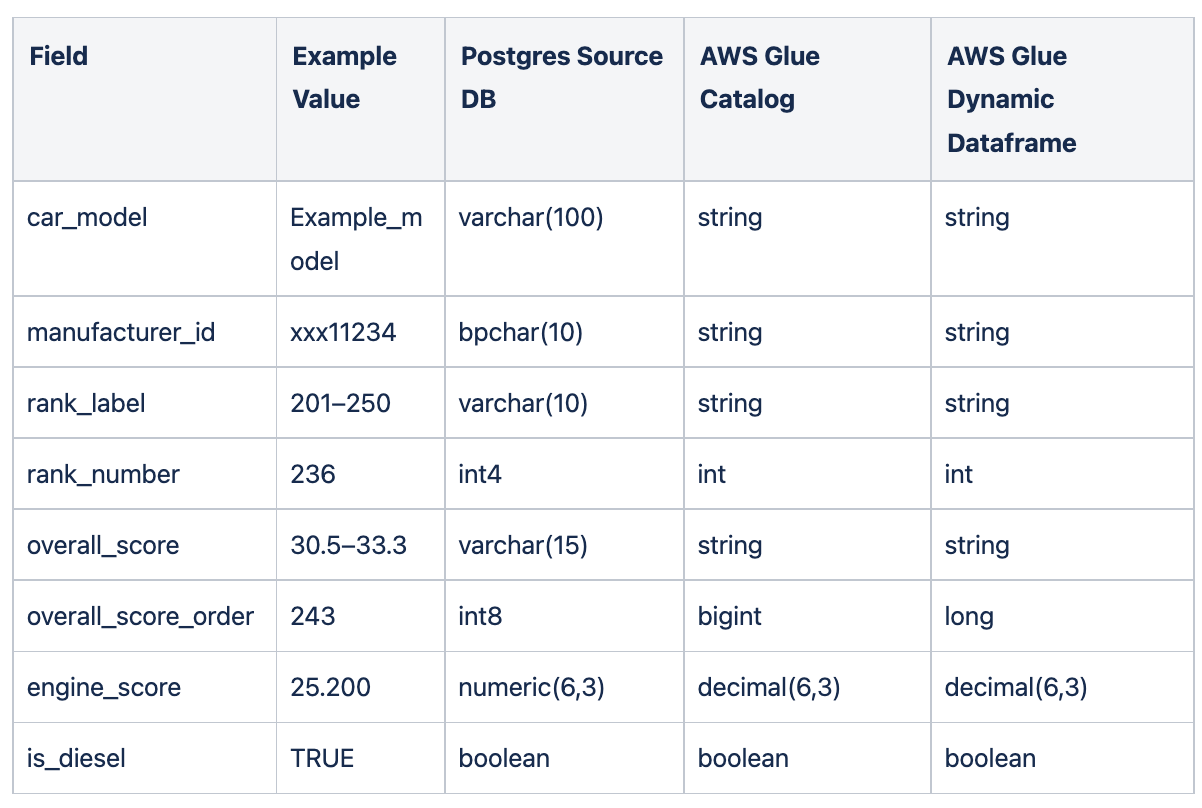
## Glue Catalog Data Types: The Secret Sauce to Your Sparkle (and Sanity!)
Let's face it, in the wild west of data, sometimes things get a little…mushy. You've got your shiny CSVs, your mysterious Parquet files, your ancient JSON relics, and maybe even a data lake that looks suspiciously like a digital swamp. You need to make sense of it all, and that's where
AWS Glue Catalog Data Types stride in, like impeccably dressed librarians for your digital library.
Think of the Glue Catalog as your central directory. It's where you register your datasets, giving them names, locations, and crucially,
defining what kind of information lives within them. And those definitions? That's where our unsung heroes, the data types, come into play.
Now, you might be thinking, "Data types? Is this going to be a snooze-fest involving abstract mathematical concepts?" Fear not, data adventurer! We're not talking about proving Fermat's Last Theorem here. We're talking about the practical magic that allows Spark to understand your data, perform complex operations, and ultimately, help you unearth those hidden gems.
### The Usual Suspects: Your Everyday Data Companions
Let's start with the bread and butter, the data types you'll encounter more often than a free coffee at a tech conference:
*
`string`: Ah, the chameleon! From names and addresses to witty tweet fragments, strings are the workhorses of textual data. Just remember, "123" is a string, not a number. Treat it with the respect it deserves (and maybe a `.trim()` now and then).
*
`integer` / `int`: For when numbers are whole and sensible. Think customer IDs, item counts, or the number of times you've said "just one more episode."
*
`long`: For those truly epic numbers. When your integer just can't cut it anymore, like tracking the cumulative number of petabytes processed by your entire organization. It's like an integer with an extra infinity in its pocket.
*
`float` / `real`: For your decimal delights. Prices, percentages, the precise amount of caffeine in your bloodstream – floats handle the nuanced numerical world. Just be aware of the occasional rounding surprise; they're a little more…artistic than precise.
*
`double`: The big brother of float. For when you need even more precision with your decimals. Think scientific calculations or the exact coordinates of that elusive Bigfoot sighting.
*
`boolean`: The simple yet powerful "yes" or "no." Is the user logged in? Is the order complete? Does this data actually make sense? Booleans are the ultimate truth-tellers.
### The Fancy Footwork: When Things Get a Little More Complex
But the Glue Catalog isn't afraid of a little sophistication. It can handle data structures that go beyond the basic:
*
`date`: For when you need to track specific days. Birthdays, order dates, the day you finally conquered that dreaded spreadsheet – dates are your temporal anchors.
*
`timestamp`: Go beyond the date and get specific with time. When was that transaction processed? What time did the server hiccup? Timestamps add that crucial temporal detail.
*
`binary`: For the binary buccaneers! This is for raw data, like images, audio files, or anything that doesn't comfortably fit into human-readable text. It's the data type for when you need to pack a punch.
*
`decimal`: The precision maestro. If you need exact decimal representation, especially for financial data, `decimal` is your knight in shining armor. No more floating-point shenanigans when dealing with your hard-earned cash!
### The Structural Superstars: When Data Gets Organized
This is where things get truly exciting, where you can represent complex relationships within your data:
*
`array`: Imagine a list of things. A list of product IDs in an order, a list of tags associated with a blog post, a list of your favorite snacks for a long coding session. Arrays are your go-to for repeating elements.
*
`map`: Think of a dictionary or a key-value store. You have a key, and it points to a value. For example, a map could store user preferences like `{"theme": "dark", "language": "python"}`. It's perfect for flexible, unstructured key-value pairs.
*
`struct`: This is where you build your own custom data types! A struct allows you to group related fields together into a single unit. Think of a `user_profile` struct containing `name` (string), `age` (integer), and `email` (string). It brings order to chaos and makes your data models much cleaner.
### Why Should You Care About Glue Catalog Data Types?
Beyond the sheer satisfaction of having your data properly categorized, here's why these little gems are crucial:
*
Spark's Understanding: Spark
needs to know what type of data it's dealing with to perform operations efficiently. Trying to perform mathematical calculations on a `string` is like asking a chef to sauté a screwdriver – it's not going to end well.
*
Data Quality: Correctly defining data types helps prevent "garbage in, garbage out." If you accidentally try to load a text file full of gibberish as an `integer`, your job just got a whole lot harder.
*
Performance Optimization: When Spark knows the data types, it can choose the most efficient algorithms for processing. Think of it as giving Spark a cheat sheet for your data.
*
Schema Evolution: As your data evolves (and it always does!), having well-defined data types makes it easier to manage changes and ensure compatibility.
### The Takeaway: Your Data Deserves a Good Name (and Type!)
The AWS Glue Catalog, and its trusty data types, are more than just technical jargon. They are the foundation of well-governed, efficiently processed, and ultimately, valuable data. So, the next time you're setting up a table in Glue, take a moment to admire those data types. They might seem small, but they're the secret sauce that keeps your Sparkle shining and your data sanity intact. Happy cataloging!