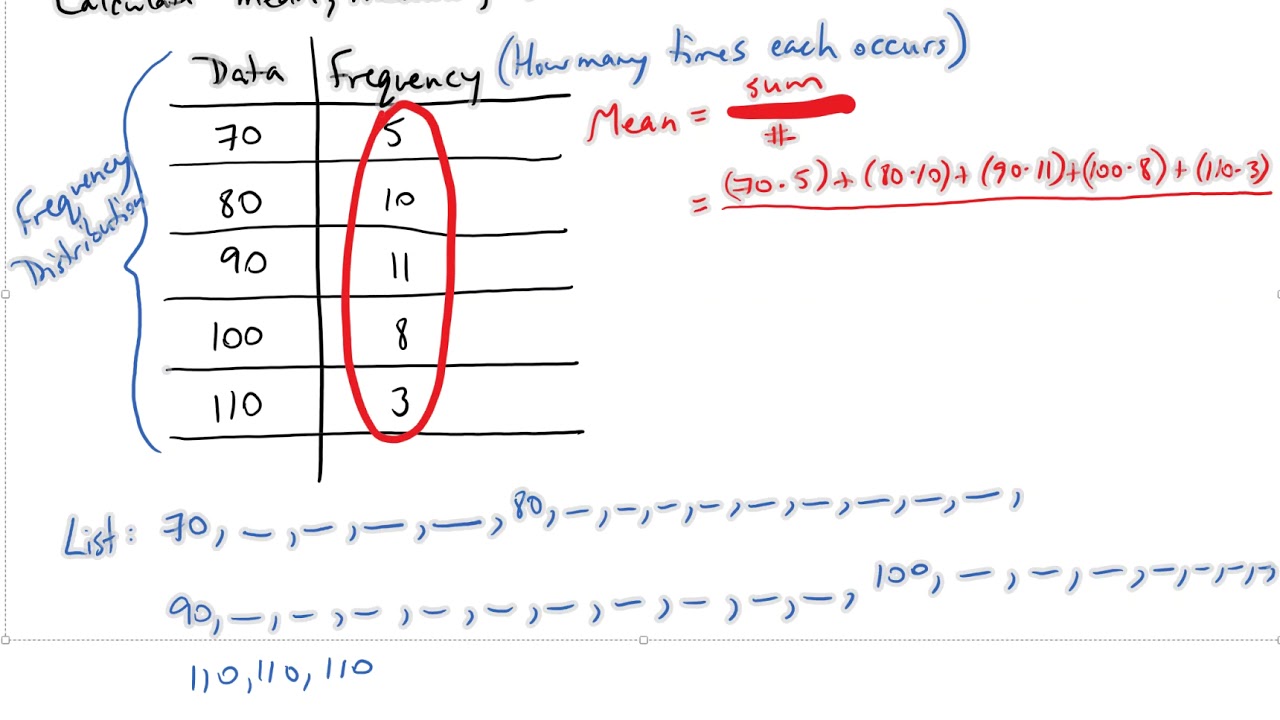
How Do You Find The Median Of A Frequency Table

Ever found yourself staring at a bunch of numbers, organized neatly into categories, and wondered, "What's the middle ground here?" You know, the number that perfectly splits your data in half? That's where the median swoops in to save the day, and today, we're going to chat about how to find it when your numbers are tucked away in a frequency table. Don't worry, it's not as scary as it sounds. Think of it like finding the middle person in a surprisingly organized line-up!
So, what exactly is a median? Imagine you've got a group of friends, and you ask them all how many pets they have. You'd probably get a few zeros, some ones, maybe a two, and if you're lucky, a super pet-lover with five! If you were to line them all up from the person with the fewest pets to the person with the most, the median would be the number of pets that the person smack-dab in the middle owns. It’s that simple!
Now, a frequency table is just a fancy way of organizing that same information. Instead of listing every single person and their pet count, it tells you, "Okay, 10 people have 0 pets, 15 people have 1 pet, 8 people have 2 pets," and so on. It's like a summary of your pet-loving (or not-so-pet-loving) community.
Why is this whole median thing so cool? Well, it's a really robust measure. What does that mean? It means it's not easily swayed by extreme values. If one person in our pet example suddenly had 100 pets (maybe a zookeeper!), the average (or mean) pet count would skyrocket. But the median? It would barely budge because it only cares about who's in the middle, not the outliers on the ends.
Let's dive into how we actually find this middle ground in a frequency table. The first, and arguably most important, step is to get your data ordered. This is crucial. Imagine trying to find the middle of a messy pile of Lego bricks – impossible! The frequency table, by its nature, often presents the data in order (like 0 pets, 1 pet, 2 pets...). If yours isn't, you'd want to sort those categories first. This is like arranging your Lego bricks by color and size.
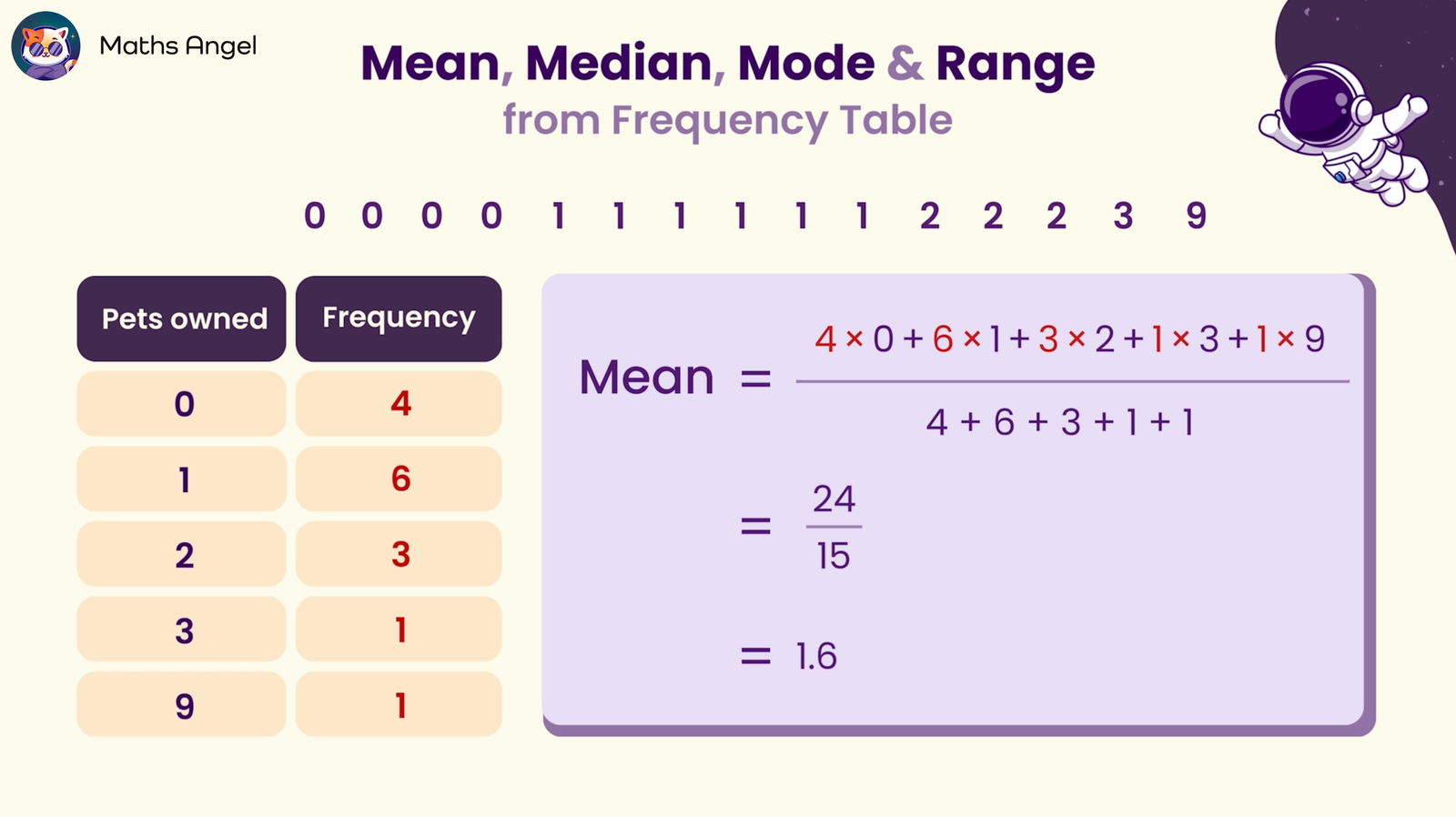
Next, we need to figure out how many data points we're dealing with in total. This is super easy with a frequency table. You just add up all the frequencies. Think of it as counting every single person (or pet, in our example) represented in your table. Let's call this total number 'N'. So, if we had 10 people with 0 pets, 15 with 1, and 8 with 2, our N would be 10 + 15 + 8 = 33.
Now, here's where the magic happens: we need to find the position of the median. If N is an odd number, like our 33, the median is located at the (N + 1) / 2 position. So, for 33 people, the median is at the (33 + 1) / 2 = 17th position. This means the 17th person in our ordered list is our median!
But how do we find out which category that 17th person falls into? This is where cumulative frequency comes into play. It's like keeping a running tally. For each category, you add up its frequency and all the frequencies of the categories before it.
Let's go back to our pet example.
Pet Counts and Who's Got 'Em
Category (Number of Pets) | Frequency | Cumulative Frequency
0 | 10 | 10 (The first 10 people have 0 pets)
1 | 15 | 25 (The next 15 people bring us to a total of 10 + 15 = 25. So, people 11 through 25 have 1 pet)
2 | 8 | 33 (The last 8 people bring us to 25 + 8 = 33. So, people 26 through 33 have 2 pets)
Remember, we were looking for the 17th position? Looking at our cumulative frequency, we see that the first 10 people have 0 pets. Then, the next 15 people (bringing us up to the 25th person) have 1 pet. Since our 17th position falls between the 11th and 25th person, guess what? The median number of pets is 1!

Easy, right? It's like following breadcrumbs through your data. You figure out where your middle position lands and then see which category that position belongs to.
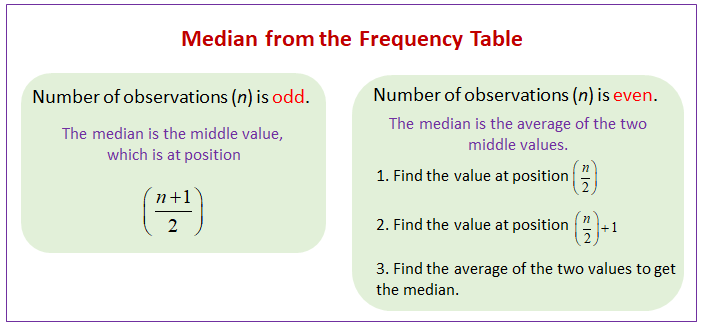
What if N is an even number? This is when things get just a little more interesting, but still totally manageable. If N is even, there isn't one single middle person; there are two middle people. The median is the average of these two middle values.
How do we find their positions? We look at the N / 2 position and the (N / 2) + 1 position. So, if we had a total of, say, 20 data points, our middle two would be at the 20 / 2 = 10th position and the (20 / 2) + 1 = 11th position.
Let's imagine a different scenario. Perhaps we're looking at the number of hours students studied for a test.
Study Hours Breakdown
Hours | Frequency | Cumulative Frequency
1 | 5 | 5 (People 1-5 studied 1 hour)
2 | 7 | 12 (People 6-12 studied 2 hours)
3 | 4 | 16 (People 13-16 studied 3 hours)
4 | 4 | 20 (People 17-20 studied 4 hours)
Our total N is 20. So our middle positions are the 10th and 11th.
Looking at the cumulative frequency:
The first 5 people studied 1 hour.
The next 7 people (bringing us to the 12th person) studied 2 hours. This means the 6th through 12th people all studied 2 hours.
Our 10th position falls within the 6th-12th group, so that value is 2.
Our 11th position also falls within the 6th-12th group, so that value is also 2.
To find the median, we average these two values: (2 + 2) / 2 = 2. So, the median study time is 2 hours.
What if our middle two values were different? Let's tweak the table slightly.
Revised Study Hours
Hours | Frequency | Cumulative Frequency
1 | 5 | 5 (People 1-5 studied 1 hour)
2 | 6 | 11 (People 6-11 studied 2 hours)
3 | 5 | 16 (People 12-16 studied 3 hours)
4 | 4 | 20 (People 17-20 studied 4 hours)
N is still 20, so we're looking at the 10th and 11th positions.
The first 5 people studied 1 hour.
The next 6 people (bringing us to the 11th person) studied 2 hours. This means people 6 through 11 studied 2 hours.
The next 5 people (bringing us to the 16th person) studied 3 hours. This means people 12 through 16 studied 3 hours.
The 10th position falls within the 6th-11th group, so its value is 2.
The 11th position also falls within the 6th-11th group, so its value is also 2.
So, the median is (2 + 2) / 2 = 2 hours.
It might seem a bit anticlimactic when both middle numbers are the same, but that's perfectly fine! It just means the median is that number. It's like flipping a coin twice and getting heads both times – the outcome is consistent!
Let's try one more quick example where the middle values are different, just to see it in action.
Another Study Session
Hours | Frequency | Cumulative Frequency
1 | 5 | 5
2 | 3 | 8
3 | 5 | 13
4 | 2 | 15
N = 15. This is odd! So we're looking for the (15 + 1) / 2 = 8th position.
Cumulative frequencies:
1 hour: up to 5 people.
2 hours: up to 8 people (people 6-8 studied 2 hours).
3 hours: up to 13 people (people 9-13 studied 3 hours).
Our 8th position falls into the 2-hour category. So, the median is 2 hours.
The beauty of the median with frequency tables is its simplicity once you understand the steps. It’s not about complex calculations, but about systematically finding the center point of your data distribution. It’s like finding the exact midpoint of a well-organized bookshelf – you know where the halfway mark is!
So, the next time you're faced with a frequency table and need to find that perfect middle value, remember the process: order your data, sum your frequencies, find the position of the median(s), and use cumulative frequency to pinpoint which category holds your middle ground. It's a skill that makes data feel a little less overwhelming and a lot more understandable. Happy medians hunting!